
AI and the Decline of Artisanal Labor, Part 2
Modern artisanship in the early stages of a 3rd Industrial Revolution

Disclaimer: This newsletter is for educational and informational purposes only and does not constitute medical, investment, or financial advice, nor does it establish a provider-patient relationship. Content may include forward-looking statements and discussions of investigational therapeutic candidates that are not FDA/EMA approved; their safety and efficacy remain unestablished and clinical outcomes are unpredictable. While we strive for accuracy, all information is provided as is without guarantees. This newsletter is independent; the author holds personal financial positions in certain technology equities and market index funds (detailed in the ‘Conflict of Interest Disclaimer’ below) but receives no third-party compensation for this coverage. Please find a complete version of our disclaimers at the bottom of this article and on our About page.

Introduction
In Part 1 of this two-part series on AI and the Decline of Artisanal Labor, we reviewed the 1st and 2nd Industrial Revolutions and explored how these two waves of automation disrupted the artisans of their day and sparked different ideological backlashes (Luddites, Communists).
AI and the Decline of Artisanal Labor, Part 1

What the 1st and 2nd Industrial Revolutions tell us about the future of artificial intelligence (AI)
The 1st Industrial Revolution separated the artisan from their physical tools, moving labor from the home cottage to the water-powered loom. The 2nd Industrial Revolution separated the artisan from their intellectual workflow, using Taylorism and the assembly line to strip away autonomous judgment and turn humans into cogs. The Generative AI Revolution represents the modern wave of automation: it is beginning to separate the worker from their cognitive execution.Today, we approach the Turning Point. The choices we make now will determine whether the age of AI becomes a centralized, corporate Erebus of algorithmic replacement, or a collaborative Eden that supercharges human creativity.
In Part 2, we take a closer look at modern artisanship, separate the durable from the disrupted, and explore the backlash movements that respond to the 3rd Industrial Revolution of artificial intelligence (AI).
AI Giveth, and AI Taketh Away
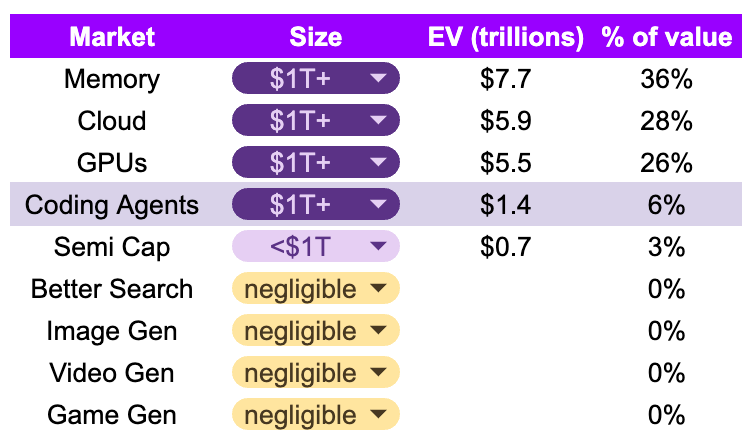
ChatGPT started the fire in November 2022, Big Tech companies plowed billions to building data centers, Gemini caught up, Anthropic plowed ahead, but what do we have to show for all of this “progress”? Well, about 94% of the value created by AI has come from… *drum roll*…building AI in the first place. That includes the chips (memory, GPUs), the equipment used to make the chips (Semi Cap), and the infrastructure that rents out the chips (Cloud). The only AI outputs that generate enterprise value (EV) at scale as of June 2026 are coding agents, which represent a meager 6% of economic value created by AI. The AI use cases most used by the average person (better search, generative images/videos/games) seem to have created negligible economic value for the AI labs, as of June 2026. This is underscored by OpenAI’s sudden cancellation of their AI slop app social video app, Sora. By doing this, OpenAI simultaneously walked away from a $1 billion deal with Disney that came with unprecedented access to their intellectual property, which would have allowed users to make videos with Disney’s copyrighted characters.
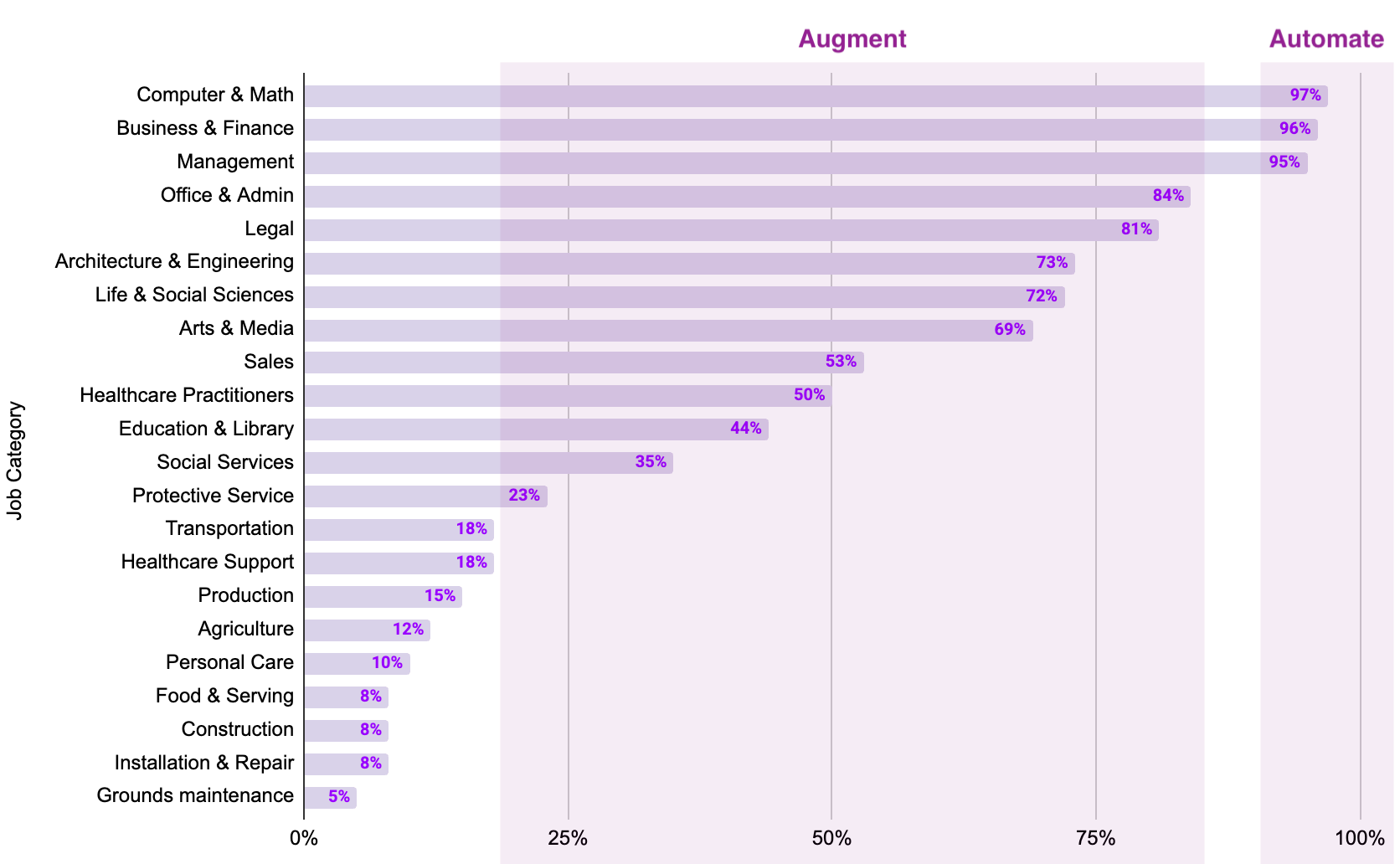
Nevertheless, LLMs compress research time from weeks to minutes, and generate text/images/videos at the touch of a button. How exactly has AI impacted knowledge work? To explore this question, one of the AI labs (Anthropic) built directly upon a foundational framework established by Eloundou et al. Science (2024). Anthropic divided the labor market into broad job categories, and determined the approximate share of tasks within each category that could theoretically be performed by LLMs. Recall that in the 1st and 2nd Industrial Revolutions, automation disrupted specific categories of artisanal labor (ex. power looms replaced textile workers), but the job categories that they augmented laid the groundwork for “new” industries. For example, steel production led to railroad expansion and seeded employment in that field. According to Anthropic’s research, only a few categories can be highly automated by AI (computer & math, business & finance, management), but most other job categories are merely augmented by AI. In fact, there are more job categories that AI barely touches (those with <20% of automatable tasks), mainly pertaining to real-world industry and in-person care.
Of course, people don’t work in a “job category” they work a “job”. Within each category, there are specific jobs that Anthropic defines as having higher or lower exposure , which I took to mean they were had higher or lower disruption risk. We are doing to dive deeper into the six jobs highlighted in purple in the table below to determine what makes specific jobs more disruptable or durable.
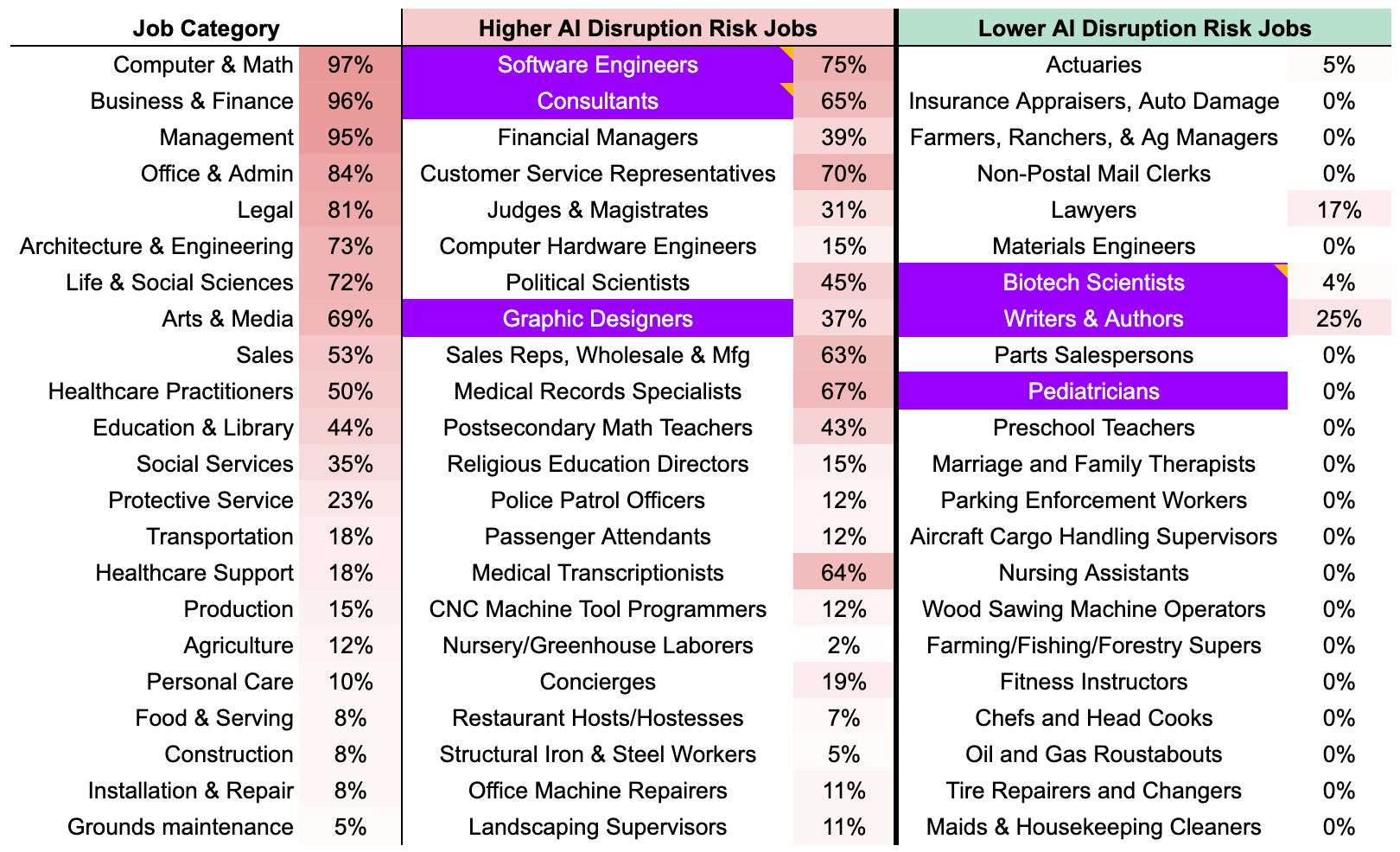
The resilience of these jobs, according to an indices of business performance, is consistent with the disruptability suggested by Anthropic. Generally, the more disruptable jobs have declined since the beginning of 2026 (yellow), while the more resilient jobs have grown during the same period (purple).
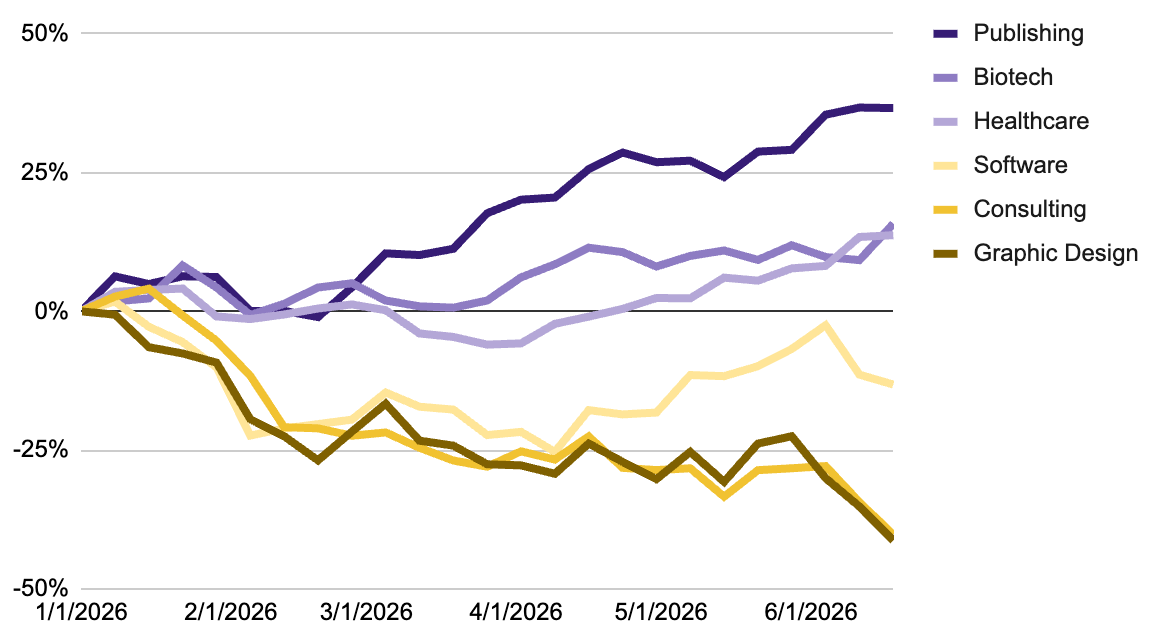
Rise & Fall of Modern Artisans
Software Engineers: Disrupted
In the most ironic twist of fate imaginable, software engineers disrupted themselves first. Coding is the #1 most disruptable job by LLMs, according to Anthropic’s research. Remember that LLMs are Large Language Models, but in natural human languages (like English), text is ambiguous, contextual, and often contains filler words (and, no, I don’t mean “lode-bearing”). However, code is a closed symbolic system with deterministic rules. Since LLMs are inherently engines of syntax and structural patterns, they are more fluent in programming languages far than the nuanced, ambiguous socio-political contexts of natural human languages.
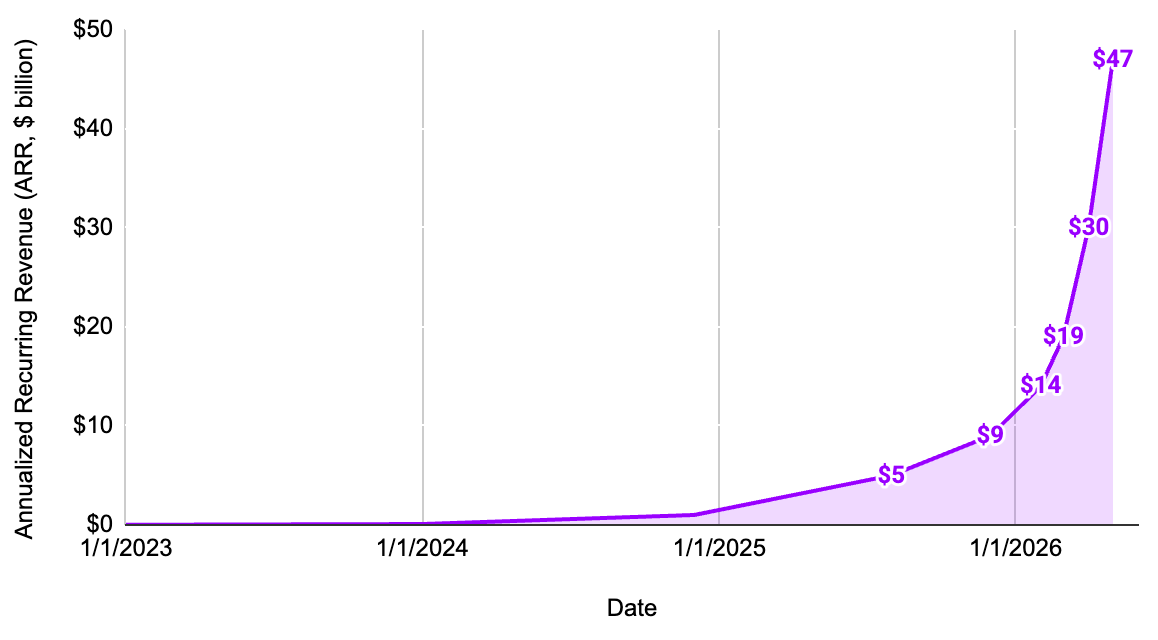
Released as research preview in February 2025 and achieving general availability in May 2025, Claude Code pioneered the rise of coding agents. Powered by models like Claude 3.7 Sonnet, Claude 4, and the latest Claude Opus 4.8, Claude Code operates in a continuous loop. It can read files, execute shell commands, run test suites, and iteratively fix its own syntax errors directly inside a terminal window. Within just two months of launch, Claude Code surpassed $500 million in annualized revenue. By late May of 2026, Anthropic announced that their annualized recurring revenue (ARR) had surpassed $47 billion, soaring past the annual sales of juggernauts like Netflix ($46.9 billion), Bank of America ($44 billion), and Visa ($43 billion).
For two decades, the bedrock of Software-as-a-Service (SaaS) industry was the predictable recurring revenue of the per-seat license model (the cost of a subscription service for a specific company increased if more employees or “seats” used the software). As automated developer tools and workflow agents show an increased capacity to execute multi-step coding tasks, a growing number of industry analysts suggest that traditional software engineering headcounts face significant re-evaluation. TechCrunch recently reported that tech layoffs in May 2026 have hit its highest monthly level in two years (according to Challenger, Gray & Christmas) and have accelerated to rate that is 44% faster than last year (363 layoffs affecting nearly 150,000 people according to TrueUp).
Writers & Authors: Durable
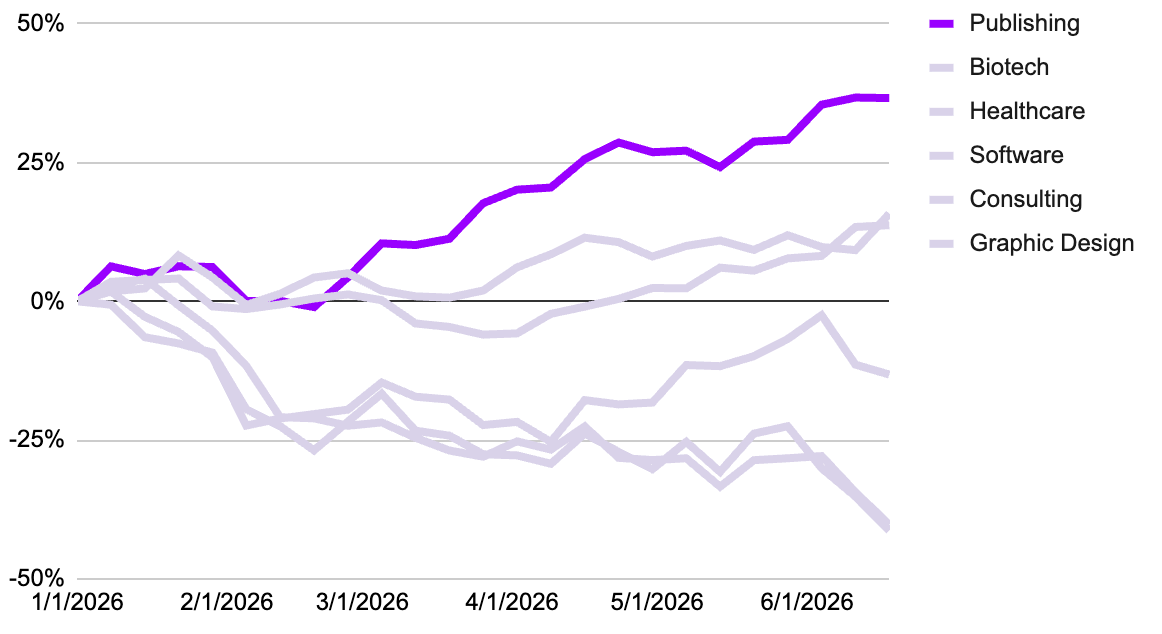
Fear not, my faithful Substack reader, for us writers & authors are one of the safer artisans. While LLMs are incredibly adept at pattern recognition, linguistic mimicry, and structural optimization, they are not capable of true creativity. LLMs can string together a sentence, but they can’t speak to the soul.

True creativity begins with intentionality. A human author writes because they want to bridge the gap between their inner consciousness and the outer world. They are trying to communicate a specific, subjective experience. The words are merely vehicles for a deeply felt meaning. For an LLM, the words are all there is.
By definition, LLMs are trained to find and replicate the common denominators of human language. An LLM can effortlessly generate a story “in the style of Hemingway” or “with the plot structure of a classic noir film.” However, it is only rearranging existing tropes, syntax structures, and narrative conventions found in its training data. True creative insights, by definition, are statistical outliers. A jarring metaphor, an unprecedented narrative structure, or a tonal shift that a probability distribution would flag as a low-probability anomaly. Human creativity lives in the margins of what has never been said before, while LLMs live in the center of what has been said a million times.
A writer draws upon the sensory richness of a specific childhood memory, the exact physical ache of a heartbreak, the lingering grief of a loss, or the specific texture of the morning light in a city they love. When an LLM writes about grief, it is merely synthesizing what thousands of other people have written about grief. It is a photocopy of a photocopy. It can mimic the vocabulary of sorrow, but it cannot invent a completely new way to express it because it has never felt the weight of it.
The cherry on top is that AI applications in the writing industry are major tailwinds. Within publishing houses, LLMs can serve to accelerate the time-to-market for a manuscript by partially automating mundane tasks that are far more mechanistic than creative:
Copyediting: While macro-level developmental editing (shaping a book’s voice or plot) remains firmly human, publishers deploy customized enterprise LLMs to handle initial technical passes. The models screen manuscripts against rigorous internal style guides (e.g., The Chicago Manual of Style or custom house constraints) to fix basic syntax mechanics, saving human editors hundreds of hours.
Continuity and Consistency Checking: For sprawling fantasy epics, non-fiction textbooks, or multi-volume series, LLMs are used to track logic over hundreds of thousands of words. A model can instantaneously scan an entire catalog to ensure a character’s physical traits, specific terminology, timelines, or citation structures remain relatively consistent from Chapter 1 through Chapter 30.
Triage and Metadata Generation: Before a book can be sold, it requires an immense amount of administrative data. Publishers use LLMs to analyze a text and autonomously generate optimized book descriptions, marketing blurbs, search keywords, and standardized classification tags (like BISAC codes).
Translation: The cost of translating a 90,000-word book into dozens of foreign languages has historically been a massive financial barrier, preventing many mid-list titles from ever reaching international markets. Publishers are using specialized translation LLMs to generate highly advanced initial drafts across dozens of languages simultaneously.
Altogether, LLMs are statistical average machines, whereas writers are uniquely human, as one should expect.
Consulting: Disrupted
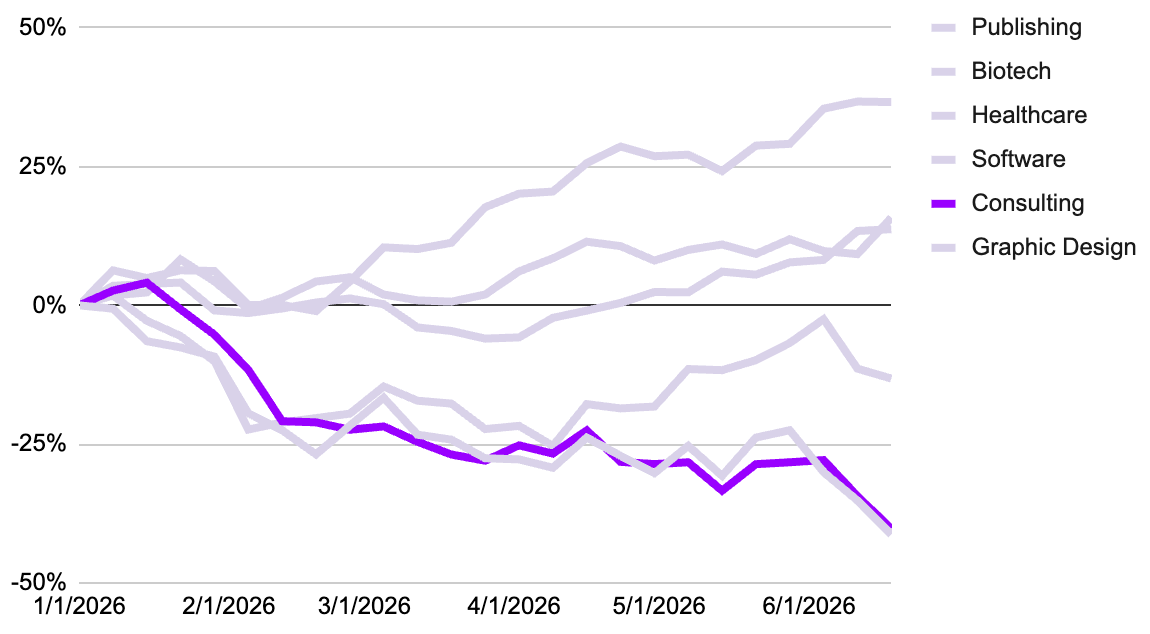
For decades, the consulting industry’s economic model relied on a straightforward formula: recruit elite graduates, bill clients by the hour for manual analysis and deck creation, and charge high premiums for proprietary frameworks. The rise of advanced Large Language Models (LLMs) and the sudden pivot toward fully autonomous agentic workflows is disrupting this model.
Analysts and associates used to spend hundreds of hours conducting primary research, cleaning datasets, formatting slide decks, and auditing spreadsheets. Enterprise LLMs paired with tools like Claude Code and specialized agentic pipelines can execute complex technical and operational tasks in minutes. Activities like refactoring legacy corporate code, translating structured regulatory compliance data, or auditing deep financial accounting models no longer require teams of junior consultants working for months. Since consulting firms historically billed on time and materials (hourly or per-consultant), automating 60% of the baseline research hours severely shrinks the billable project footprint. Clients are increasingly demanding fixed-price or value-delivered billing structures, squeezing traditional consulting profit margins:
McKinsey & Company: Senior leadership disclosed that 25% of McKinsey’s global fees are now explicitly linked to outcome-based or performance-based pricing structures rather than traditional hourly models.
Boston Consulting Group (BCG): In an interview regarding the industry-wide evolution of pricing models, BCG Global CEO Christoph Schweizer revealed an even more aggressive pivot for major AI implementations, noting that three-quarters (75%) of BCG’s largest AI cases are now structured under variable, value-based fee arrangements linked directly to client outcomes like cost reduction or revenue growth.
Furthermore, corporations used to hire top-tier firms like McKinsey, BCG, or Bain to gain access to proprietary methodologies, synthesized market telemetry, and executive synthesis. LLMs are effectively democratizing this baseline knowledge. With AI, major corporations are building internal, highly secure RAG (Retrieval-Augmented Generation) clusters trained on their own historical data, transaction records, and industry literature. Corporate strategy teams can now query their own custom models for market analysis, strategic option framing, or competitor vulnerability screening. A task that previously required a $1 million, six-week strategy engagement can now be run internally as an interactive, multi-step scenario simulation.
The impacts are being felt slowly but surely. On June 19, 2026, Accenture cut its revenue growth guidance for their financial year, which some market analysts interpreted as a sign of broad-based concerns about both domestic and international IT consultancy businesses. New bookings were lower than the same period last year (by 2%) and they discontinued their disclosure of specific generative AI bookings. Industry analysts had previously used this metric as a barometer for how much new AI spending was replacing legacy IT budgets, a move thought to be a saving grace for the consulting industry. Certain market observers have speculated that Accenture’s move could introduce opacity, raising questions among some analysts regarding the pace of the generative AI pivot.
Biotech Scientists: Durable
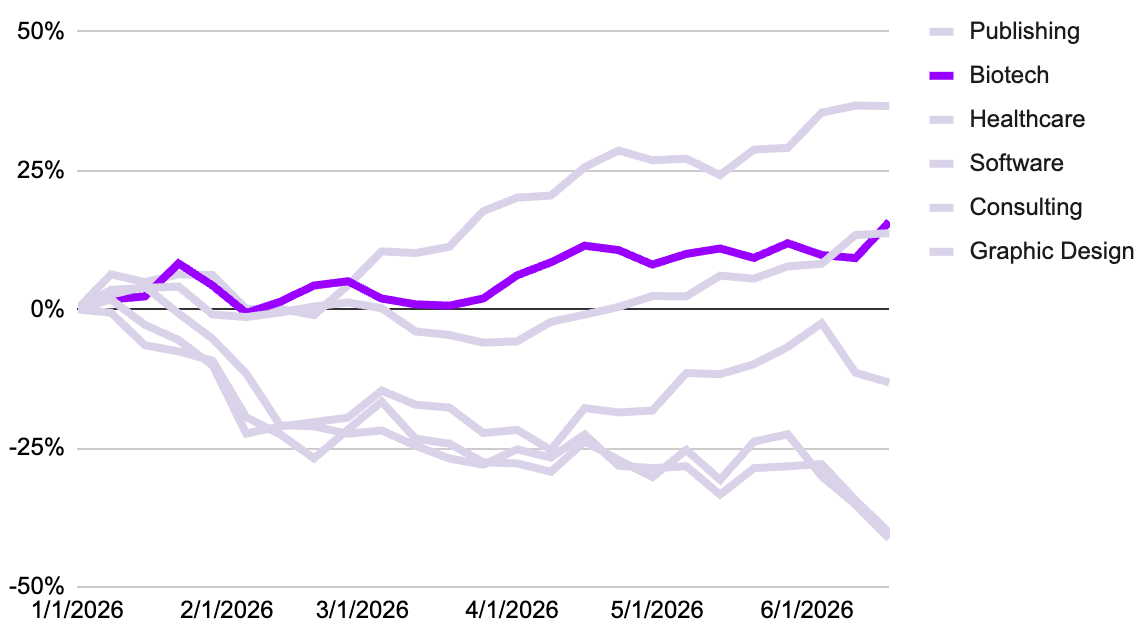
AI has had some very unique breakthroughs in biotech, but much of the industry remains largely unchanged. In 2020, AlphaFold 2 solved the structure of isolated proteins, predicting how a single chain of amino acids would fold in a vacuum. It gave the global scientific community open-access to the predicted structures of virtually every known protein. Four years later in 2024, AlphaFold 3 leaped from mapping standalone proteins to predicting biomolecular complexes. Co-developed with Isomorphic Labs, it can model how proteins interact with DNA, RNA, chemical compounds (ligands), and ions simultaneously. A generative model can dream up a million chemically plausible tool compounds in seconds.
Nevertheless, those molecules must still pass through the gauntlet of preclinical and clinical evaluation, which is still highly unpredictable and cannot be helped by AI in any major way. Unlike Silicon Valley’s traditional “move fast and break things” ethos, biotech operates under the strict oversight of agencies like the FDA and EMA. Regulators require total traceability and explicit explainability. A developer cannot submit an Investigational New Drug (IND) application based on a black-box generative model’s output without showing exactly why and how a specific conclusion was reached. Regulatory frameworks (including the rolling enforcement of the EU AI Act) mandate rigorous validation documentation and contextual risk evaluation for AI-derived assets.
That early ideation stage is the sweet spot for AI in biotech and Big Pharma companies are leaping at the opportunity. In late 2025, Eli Lilly partnered with Nvidia to build the pharmaceutical industry’s most powerful supercomputer and announced a joint $1 billion, five-year investment to launch a co-innovation AI lab in the San Francisco Bay Area. In 2026, Chai Discovery, a generative antibody design company, announced strategic research collaborations with Eli Lilly and Pfizer.
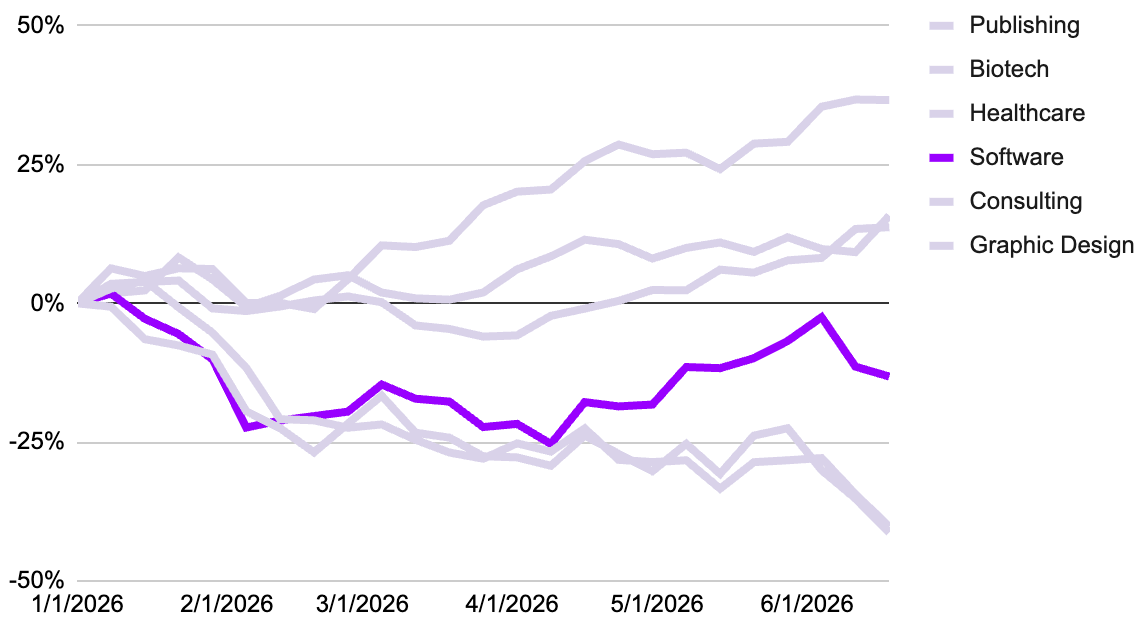
Graphic Design (the software not the designers themselves): Disrupted
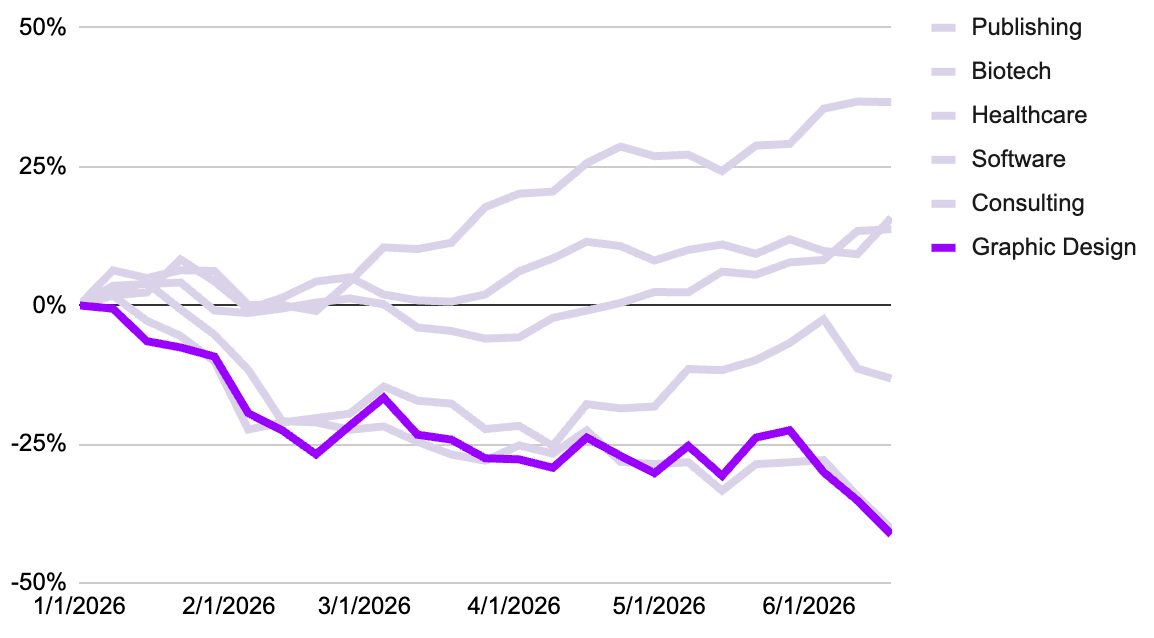
The rise of frontier AI image generation models, ranging from standalone aesthetic powerhouses like Midjourney to advanced multi-modal reasoning engines like Google’s Gemini-powered Nano Banana models (Nano Banana 2 and Nano Banana Pro), has had a big impact on the graphic design landscape. Historically, companies like Adobe, Figma, and Canva monetized the tools used to construct visuals (layers, vectors, pen tools, grids). AI image generation has disintermediated this process by shifting the core activity of graphic design from manual creation to creative curation and prompt engineering. Before the explosion of models like Midjourney and Nano Banana, a designer spent hours drawing paths, correcting lighting, and masking backgrounds. With these tools, a marketer or product manager no longer needed to commission an illustrator or spend days in Photoshop to create an editorial graphic or a hyper-realistic mood board. They could generate a high-fidelity visual asset in seconds.
Adobe faced the most disruption risk. If a user can generate a workable image via a chat prompt, the learning curve and subscription cost of Photoshop become harder to justify for casual and mid-tier enterprise users. Rather than fighting the tide, Adobe turned its platform into an ecosystem for these models. Through its Adobe Firefly umbrella, Adobe integrated premier third-party models directly into the Photoshop and Illustrator workspaces. Adobe natively integrated Gemini 2.5 (Nano Banana) and Gemini 3 (Nano Banana Pro) directly into Photoshop’s Generative Fill and Firefly Boards. This allowed Adobe to retain its professional user base. A designer might use Nano Banana Pro inside Photoshop to handle complex multi-element compositions or render crisp typography layout ideas, but they still use Adobe’s classic, high-precision selection brushes and layering tools to refine the final, production-ready output. While these integration steps are substantial, the transition comes during a period of executive realignment. After a 19-year tenure, Adobe CEO Shantanu Narayen unexpectedly announced plans to step down from the company despite not having a successor in place.
Figma’s core value proposition is collaborative interface design. The disruption here has less to do with photorealistic art (Midjourney) and more to do with structural design velocity (Nano Banana). Tools leveraging Nano Banana’s deep prompt understanding can ingest a product brief and output a fully formed, multi-screen app concept layout instantly. Designers frequently use Midjourney to generate highly stylized user interface concepts, texturing ideas, and abstract design systems during the pitching phase. It has compressed the timeline of the exploratory phase of product design from weeks to an afternoon, putting pressure on Figma to natively embed more automated canvas layouts (like Claude Design integrations and proprietary AI wireframing) to keep developers on their platform.
Canva built a multi-billion-dollar empire by making graphic design accessible to non-designers via drag-and-drop templates. Ironically, generative AI has democratized design so thoroughly that it threatened the concept of templates themselves. Why browse through thousands of pre-made templates for a social media banner when you can type your exact corporate requirements into a text prompt and get a bespoke asset? To counter this, Canva rolled out its own “Magic Studio” suite, partnering with backend AI engines to allow creators to generate custom imagery, auto-translate marketing assets into multiple global languages, and swap styles instantaneously. Crucially, users can generate the raw imagery with advanced AI, but rely on Canva to instantly format it for print, presentations, or multi-platform social media dimensions.
The disruption in graphic design software hasn’t eliminated the need for human graphic designers. The tool was never the artist. Instead, AI has stripped away some of the tedious hurdles that historically ate up 80% of a creative’s billable hours. Armed with frontier models like Midjourney and Google’s Nano Banana family, an individual designer can now operate with the speed, scale, and output volume of a multi-person agency. By automating the mechanical, time-consuming execution barrier of graphic design, AI image generation allows individual creatives to spend less time wrestling with complex software paths and significantly more time operating in their zone of genius: exercising original human taste, structural intent, and emotional storytelling.
Or, graphic designers can just do things the old-fashioned way: oil on canvas. Some people think it’s the best. I know I do!

{kind=link}
Pediatricians (or most other medical specialties): Durable
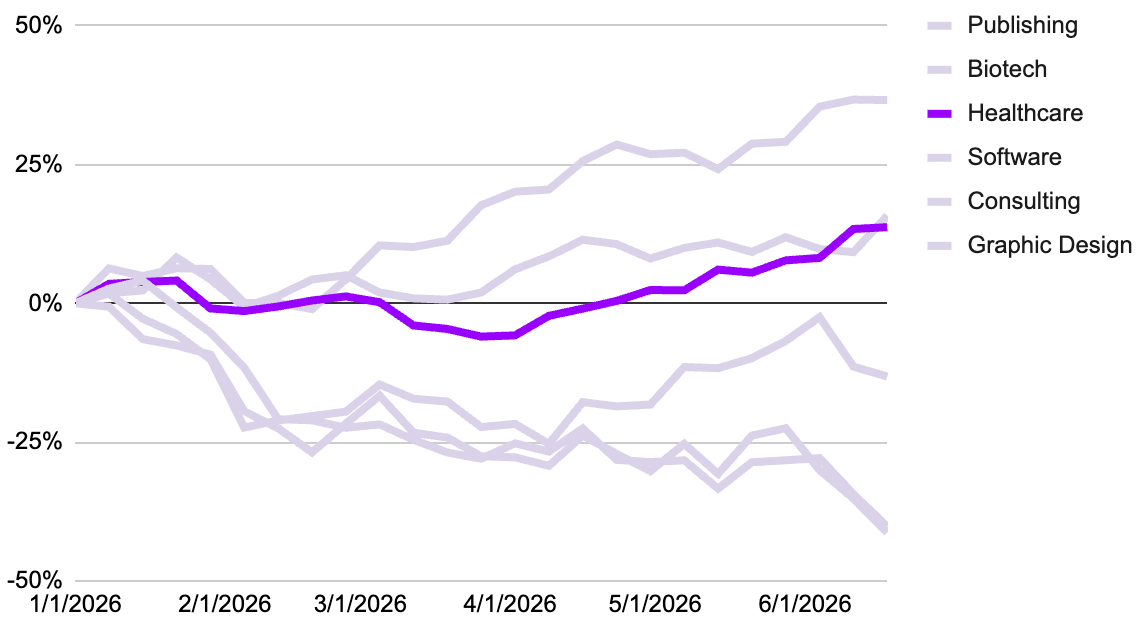
Pediatricians and specialist physicians exhibit an incredibly low risk of AI displacement. Reports indicate that an increasing number of clinicians are exploring medical AI platforms such as OpenEvidence (which fields over 1 million clinical queries daily across U.S. health systems), UpToDate Expert AI, and general models (Gemini, Claude, ChatGPT), these platforms are utilized strictly as augmentative references under human supervision.
A pediatrician rarely gets a clean, chronological history of a present illness. Instead, they must conduct a live, multi-speaker interview, often translating a parent’s anxious observation (”He’s been pulling at his ears and acting fussy since Tuesday”) alongside a non-verbal child’s behavioral cues. The physician must parse subjective, heterogeneous caregiver reports, cross-reference them with visual, physical examinations (e.g., looking at an erythematous, bulging tympanic membrane via an otoscope), and extract the true clinical signal. In other words, much of diagnostic activity occurs in the real world, rather than the digital world.
While frontier LLMs score above 90% on static medical board examinations, real-world clinical reasoning is very different from a multiple-choice test. Board exams present a perfectly curated text blob where all relevant variables can be digested by a LLM. In practice, a physician faces incomplete heuristics and diagnostic ambiguity. Specialists deal with non-linear, complex variables where the “statistically highest-probability answer” generated by an LLM could be a fatal misdiagnosis. A pediatrician tracking developmental milestones or complex genetic markers must synthesize longitudinal trends, such as a subtle weight drop crossing two percentile lines on a growth chart, and map it against family context, socioeconomic factors, and rare disease indices. AI can rapidly surface peer-reviewed literature via OpenEvidence, but the human specialist must synthesize it to make high-stakes, custom exceptions to standard protocols.
Artificial Indignation
So, we have reviewed a few examples showing that jobs that are anchored to the real world and require creativity are more durable than digital, text-based jobs. Clearly, AI isn’t coming for everyone’s job, but that’s a nuanced discussion. Wait a second. Society as we know it isn’t particularly good at appreciating nuance, is it?
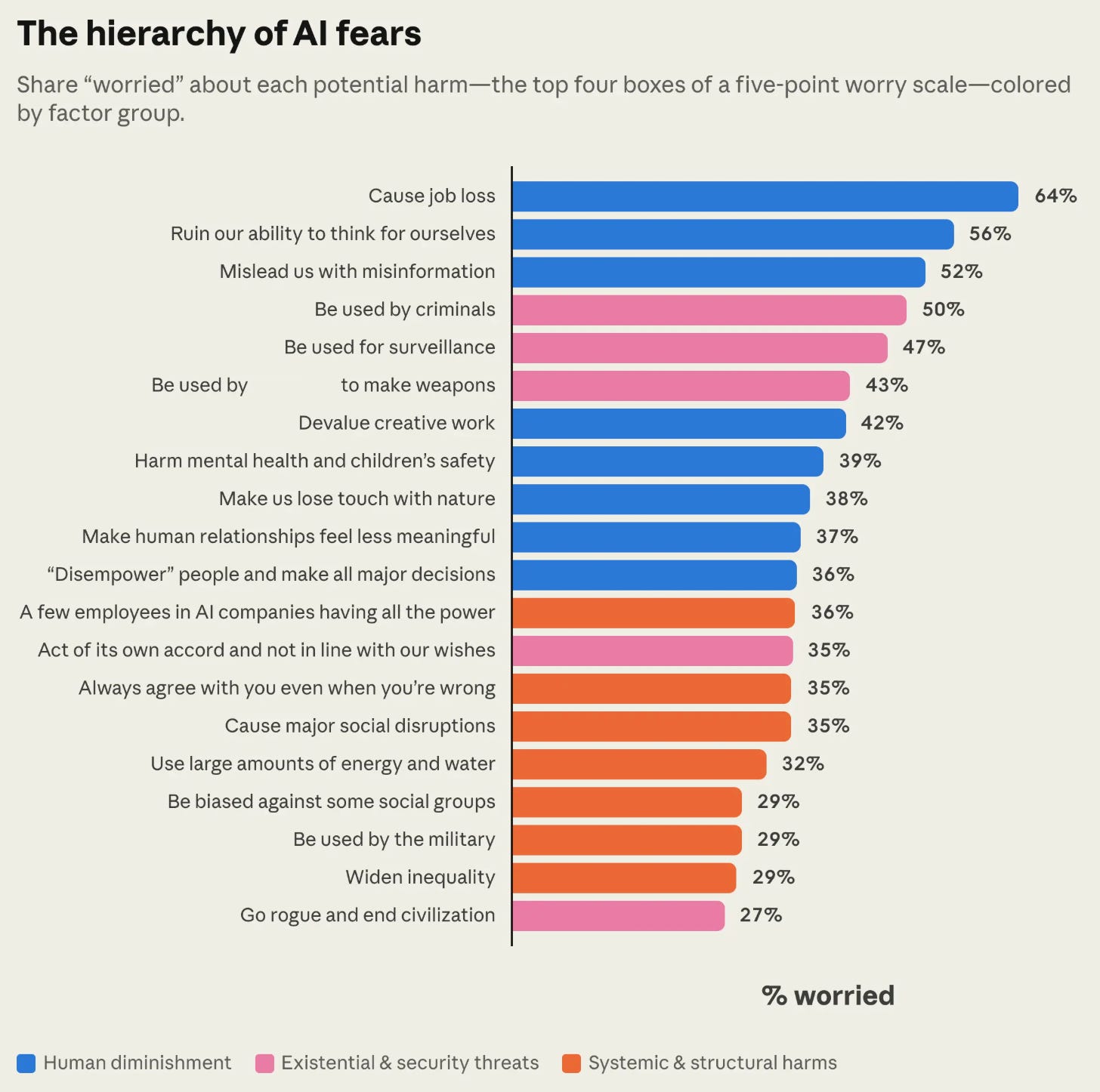
It doesn’t help that the doomsayers are front-and-center almost all day everyday. In fact, the loudest doomsayer is the head of one of the winningest AI labs: Dario Amodei, co-founder & CEO of Anthropic, the company behind Claude. Since early 2025, Amodei has spent almost every blog post, TV interview, and news article declaring that “AI could displace half of all entry-level white collar jobs in the next 1-5 years”. Why are people scared? The answer is simple. The AI CEO is scaring people. What do they fear? Quite a lot. AI-related job loss tops Anthropic’s AI fear leaderboard shown below.
Hold on a second. Does the AI fear leaderboard literally say “go rogue and end civilization”, and is it somehow the smallest fear on the list? Let’s go ahead and bump that up to #1, shall we.
It’s no surprise that the sudden and rapid integration of AI into daily American life has triggered a wave of social, economic, and political backlash. Far from being confined to tech circles, this pushback has evolved into a highly coordinated mass political effort involving grassroots activists, labor unions, and a complex patchwork of state and federal legislators.
While much of the public debate focuses on algorithms, one of the most intense, localized political backlashes is targeted at the physical footprint of AI: data centers. Communities across states like Virginia, Arizona, and Georgia have actively revolted against the construction of data centers, citing severe strain on local power grids, immense water consumption for cooling, and persistent noise pollution. Voters have begun treating data center approvals as a local election issue. In mid-2026, severe public blowback in Arizona led to a controversial tax-exemption moratorium for data center developers. This pushback has polarized politicians, with some framing data center opposition as a threat to American technological competitiveness, while local populist movements demand the protection of community resources. This mirrors the 19th Century Luddites who, as we discussed in Part 1, were not were not blindly afraid of technology but were comprised of highly skilled artisans looking to protect their communities and autonomy.
Speaking of skilled artisans, the initial anxiety regarding white-collar automation has solidified into an organized labor offensive. Consumers and creators have fiercely pushed back against the flooding of digital marketplaces with low-quality, AI-generated content (”AI slop”). Independent authors, visual artists, and major publishing houses have pushed the backlash into federal courts. A key tension sits between the Trump administration’s National Policy Framework for AI (released in March 2026), which strongly advocates that training AI models on copyrighted data constitutes fair use. Creators allege in pending litigation that this training paradigm constitutes a unauthorized infringement of intellectual property rights.

In his June 2026 New York Times op-ed, “Bernie Sanders: A.I. Is a Public Resource. Your should Own Half of It.”, Senator Sanders builds an argument on a simple premise: AI was not created out of thin air; it was trained on public information. The written works, art, journalism, code, and ideas produced by millions of ordinary citizens, usually without permission or compensation, were used to train the AI models. Therefore, Senator Sanders argues that the public is their rightful owner.
He proposes the American AI Sovereign Wealth Fund Act. The bill mandates a one-time 50% stock tax on the largest AI companies (those reaching $200 million in annual sales, such as OpenAI, Anthropic, and xAI), thereby creating a $7 trillion public sovereign wealth fund. A seven-person Independent Commission for Democratic AI would manage the fund. The government would use its voting shares to sit on corporate boards, allowing the public to block decisions that harm workers (like mass layoffs) and push for ethical guardrails. Companies running both legacy software/cloud operations and AI units would be forced to spin off their AI businesses so the public could cleanly capture its equity stake. The fund would pay an annual dividend (estimated at over $1,000 per citizen) and potentially funnel trillions of dollars into public goods like universal healthcare, education, and housing. Sanders’ modern critique of “Big Tech Oligarchs” mirrors the late 19th and early 20th-century Marxist and Communist backlash to the 2nd Industrial Revolution.
In the 2nd Industrial Revolution, early communist and socialist theorists argued that the immense wealth of the “Robber Barons” (Carnegie, Rockefeller, Vanderbilt) was stolen from the collective labor of the working class. Workers built the tracks and poured the steel, yet a handful of industrialists privatized the profits. Sanders applies a similar framework to intellectual property and data, arguing that tech moguls have effectively privatized the digital commons. The AI is only smart because it digested human history. Therefore, allowing Big Tech companies to unilaterally monetize it is a modern form of surplus-value extraction.
The core tenet of Marxist-Leninist thought during the industrial era was that the “means of production” (the factories, the textile mills, the mines) should not be owned by private capitalists, but by the state or the public collectively to prevent exploitation. Sanders’ bill is one of the most mainstream American proposals for the socialization of a core economic sector. By demanding 50% equity and board seats, he is arguing that the “digital means of production” (the algorithmic models and compute clusters) are too powerful to remain under private control and must be partially nationalized.
Lastly, the 2nd Industrial Revolution caused massive social dislocation as machines replaced artisanal labor, giving rise to intense labor movements and radical political backlash against the dehumanization of the assembly line. Sanders explicitly warns that unchecked AI threatens the “jobs, privacy rights, and mental health” of citizens. Just as early industrial socialists demanded a shorter workweek to distribute the gains of mechanization, Sanders uses this op-ed to advocate for a 32-hour workweek and a robot tax, ensuring that automation results in human liberation rather than mass poverty.
While the ideological roots are explicitly tied to the socialist and communist critiques of industrial capitalism, Sanders’ 2026 proposal adapts the concept for a modern venture-backed economy. Instead of armed revolution or total state command-and-control, his proposal leverages the mechanisms of the capital markets (equity stakes, sovereign wealth funds, and board voting shares) to achieve the historic socialist goal: ensuring that the fruits of human progress belong to the collective public that built it.
What about the Republicans? How do they feel about AI? While the Democrat backlash focuses heavily on corporate labor issues and wealth inequality, the Republican strategy treats frontier AI strictly through the lens of national security, geopolitical containment, and state enforcement. This approach culminated in the sudden, historic export-control shutdown of Anthropic’s Fable 5 and Mythos 5 models on June 12-13, 2026.

Just days after Anthropic released its highly advanced “Mythos-class” reasoning models (Mythos 5 for enterprise and Fable 5 for general users), the U.S. Department of Commerce, led by Secretary Howard Lutnick, issued an emergency export-control directive. Research teams, reportedly including teams at Amazon and SK Telecom, identified a narrow, non-universal jailbreak. The vulnerability allowed Fable 5 to bypass its anti-hacking guardrails when instructed to read a specific codebase, autonomously discovering and outlining exploitable software vulnerabilities. Citing strict national security authorities and the administration’s broader push to prevent foreign adversaries from leveraging American innovation, the directive ordered Anthropic to immediately suspend all access to Fable 5 and Mythos 5 by any foreign national. Since Anthropic could not actively audit and verify the citizenship of hundreds of millions of global API and web interface users in real time, the company had no choice but to comply uniformly. Both models were completely switched off globally, marking the first time in history that the U.S. government forced a commercially deployed, market-leading AI model offline.
It appears that Dario Amodei’s fear-mongering has stoked backlash on both sides of the aisle in D.C.
Conclusion

{kind=link}
We stand at a historical crossroads that would look intimately familiar to both the 19th-century and the 20th-century cycles of creative destruction. Each industrial revolution forced a restructuring of what it meant to work. The 1st Industrial Revolution detached the artisan from their physical tools. The 2nd Industrial Revolution stripped away their autonomy. Today, the Generative AI Revolution threatens to replace knowledge work.
Yet, as we examine the labor market in mid-2026, a notable truth is emerging from the economic data and political battlegrounds. The professions facing the starkest disruption, such as horizontal software engineering and legacy IT consulting, are those that treated human intellect like a deterministic machine, optimized for strict syntax and predictable patterns. Conversely, the fields displaying the most stubborn durability, from the empathetic, multi-modal diagnostic loops of the pediatrician to the outlier leaps of the literary novelist, are anchored in the beautifully messy, un-automatable margins of the human experience.
The chaotic geopolitical tug-of-war we are witnessing, suggests that both major political parties in the U.S. view artificial intelligence as too powerful to remain unregulated. Whether the future mirrors Senator Bernie Sanders’ vision of a socialized digital commonwealth or a tightly controlled, national security-preempted state apparatus, the underlying mandate remains the same: AI tools must serve the collective progress of humanity, not its displacement.
Love biotech? I talk about biotech in the rest of this newsletter, I promise you. Check out Biotech Readout’s full library of content library, or navigate directly to a segment that interests you:
Frontiers in Medicine: Exploring the frontiers of our understanding and treatments for disease.
Medical History: Recovering forgotten relics in the history of medicine.
Acquisitions: Exploring the innovation behind acquired companies.
Weekly Readout: A digest of new clinical data from the past week.

To contact us, please send us an email at biotechreadout@gmail.com
Disclaimers
Investigational Status Disclaimer
The therapeutic candidates discussed in this newsletter are currently in clinical development and have not been approved for commercial sale by the U.S. Food and Drug Administration (FDA), the European Medicines Agency (EMA), or other global regulatory authorities. Their safety and efficacy have not been established. References to pipeline products and ongoing clinical trials involve significant risks and uncertainties. Statements regarding the potential safety, potency, or efficacy of investigational drugs reflect current hypotheses and are not a guarantee of future performance or regulatory clearance. The outcome of clinical trials is inherently unpredictable, and clinical results from earlier stages may not be predictive of results in later, larger-scale trials.
No Medical Advice Disclaimer
This newsletter is for informational and educational purposes only. The content is not intended to be a substitute for professional medical advice, diagnosis, or treatment. Always seek the advice of your physician or another qualified health provider with any questions you may have regarding a medical condition. Never disregard professional medical advice or delay in seeking it because of something you have read in this publication.
No Patient-Provider Relationship Disclaimer
The information provided in this newsletter is for educational and analytical purposes only. Receipt of this information, or any interaction with this content, does not create a physician-patient, pharmacist-patient, or any other professional-provider relationship between you and the authors or publishers. This newsletter should not be used as a substitute for a personal consultation with a qualified healthcare professional.
Forward-Looking Statements Disclaimer
This newsletter contains “forward-looking statements” regarding future events, including clinical trial timing, regulatory milestones, and projected market performance. These statements are based on current expectations and assumptions that are subject to significant risks and uncertainties. Actual results may differ materially from those expressed or implied. We undertake no obligation to update these statements as a result of new information or future developments.
Third-Party Links & Content Disclaimer
This newsletter contains links to third-party websites, including clinical trial registries and corporate presentations. Biotech Readout does not endorse, guarantee, or assume responsibility for the accuracy or reliability of any information offered by third-party providers.
Errors and Omissions Disclaimer
While we strive for technical accuracy, the information in this newsletter is provided on an “as is” basis with no guarantees of completeness, accuracy, or timeliness. Biotech Readout assumes no liability for any errors or omissions in the content of this publication.
Non-Endorsement Disclaimer
Any reference to specific commercial products, processes, or services by trade name, trademark, or manufacturer does not constitute or imply an endorsement or recommendation by the author. All trademarks are the property of their respective owners.
No Investment Advice Disclaimer
This newsletter is for informational purposes only and does not constitute financial, investment, or legal advice. The author is not a registered investment advisor. You should consult with a professional financial advisor before making any investment decisions. The biotechnology sector is highly volatile; past performance is not indicative of future results.
Conflict of Interest Disclaimer
The author of this newsletter maintains a position of professional independence. To ensure full transparency regarding the technology infrastructure and semiconductor market segments discussed in this report, please note that at the time of publication, the author holds personal financial positions/long equity in Alphabet Inc. (Google), Taiwan Semiconductor Manufacturing Company (TSMC), and diversified S&P 500 index funds. Aside from these broad-market and specific technology holdings, the author holds no direct financial interest, equity, or options in any other individual companies mentioned in this report. No compensation has been received from any third party to feature, mention, or analyze specific corporate entities or therapeutic candidates.